Consultas Avanzadas
Las consultas avanzadas son la clave para desbloquear el verdadero poder de una base de datos, permitiéndote manipular, agregar y analizar tus datos de formas que serían imposibles con solo las operaciones básicas. Dominar JOIN, GROUP BY, HAVING y las subconsultas es un hito importante en el aprendizaje de SQL y la gestión de datos.
¿De que trata?
Las consultas avanzadas en bases de datos van más allá de simplemente seleccionar, filtrar y ordenar datos de una sola tabla. Permiten realizar operaciones más complejas y potentes, como combinar información de múltiples tablas, agregar datos en grupos y filtrar esos grupos en función de condiciones específicas. Son esenciales para extraer conocimientos más profundos y resumir grandes volúmenes de información, lo que es fundamental para la toma de decisiones y la creación de informes complejos.
Mientras que las consultas básicas son como pedirle al bibliotecario un libro específico, las consultas avanzadas son como pedirle un informe detallado que diga: "Muéstrame la cantidad total de libros por cada autor que ha escrito más de diez libros y organiza esta información por género". Esto requiere combinar datos de autores y libros, contarlos, agruparlos y luego aplicar un filtro a esos grupos.
Estas consultas son la columna vertebral de la inteligencia de negocios y del funcionamiento de muchas aplicaciones que necesitan procesar y presentar datos de forma sofisticada.
¿Cómo se hacen las Consultas Avanzadas?
Las consultas avanzadas utilizan extensiones y cláusulas adicionales de SQL (Structured Query Language). Vamos a explorarlas con ejemplos, utilizando la misma lógica de tablas que hemos visto antes, pero añadiendo una tabla Autores para ilustrar los JOINs:
Tabla Autores:
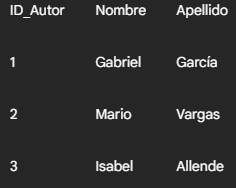
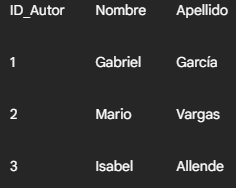
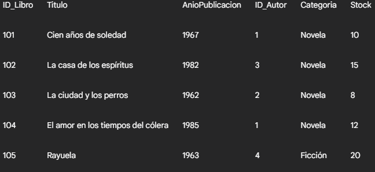
Tabla Libros:
1. JOIN (Unir)
¿De qué trata? La cláusula JOIN se usa para combinar filas de dos o más tablas basándose en una columna relacionada entre ellas. Es el mecanismo fundamental para trabajar con bases de datos relacionales, ya que te permite reunir información que está distribuida en diferentes tablas.
¿Cómo se hace? Hay varios tipos de JOIN, pero el más común es INNER JOIN.
INNER JOIN: Devuelve solo las filas donde hay una coincidencia en la columna de unión en ambas tablas.
Sintaxis:

Para copiar:
SELECT columnas
FROM TablaA
INNER JOIN TablaB ON TablaA.columna_comun = TablaB.columna_comun;
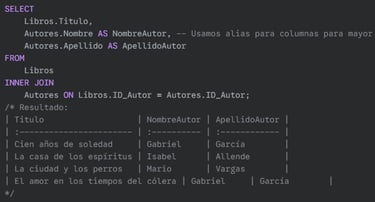
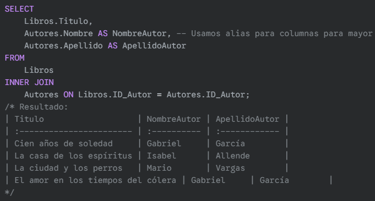
Ejemplo: Obtener los títulos de los libros junto con el nombre y apellido de su autor.
SQL:
Otros tipos de JOIN:
LEFT JOIN (o LEFT OUTER JOIN): Devuelve todos los registros de la tabla izquierda (FROM TablaA), y los registros coincidentes de la tabla derecha (TablaB). Si no hay coincidencia en la derecha, los campos de la tabla derecha serán NULL.
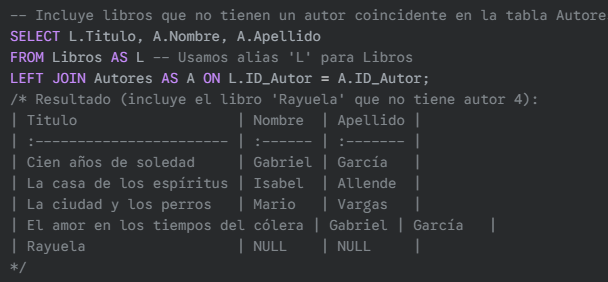
SQL:
RIGHT JOIN (o RIGHT OUTER JOIN): Similar a LEFT JOIN, pero devuelve todos los registros de la tabla derecha y los coincidentes de la izquierda.
FULL JOIN (o FULL OUTER JOIN): Devuelve todos los registros cuando hay una coincidencia en cualquiera de las tablas (registros de la izquierda que no coinciden con la derecha, y viceversa).
2. GROUP BY (Agrupar Por)
¿De qué trata? La cláusula GROUP BY se usa para agrupar filas que tienen los mismos valores en una o más columnas especificadas en un conjunto de resumen. Cuando se usa GROUP BY, a menudo se combinan con funciones de agregación (como COUNT, SUM, AVG, MIN, MAX) para realizar cálculos sobre cada grupo.
¿Cómo se hace? Se coloca después de FROM y WHERE (si están presentes), y se especifica la columna o columnas por las que agrupar.
SQL:


Ejemplo: Contar cuántos libros hay por cada categoría.
Para copiar:
SELECT columna_a_agrupar, funcion_agregacion(columna_a_calcular)
FROM Tabla
[WHERE condiciones]
GROUP BY columna_a_agrupar;
SQL:
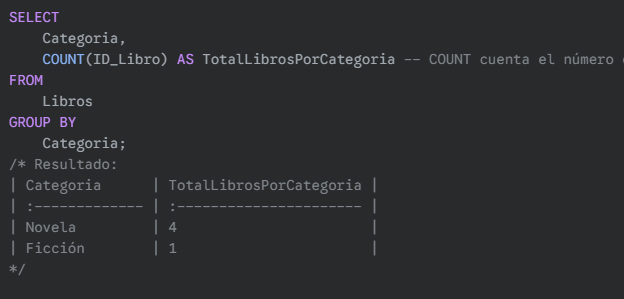
Para copiar:
SELECT
Categoria,
COUNT(ID_Libro) AS TotalLibrosPorCategoria
FROM
Libros
GROUP BY
Categoria;
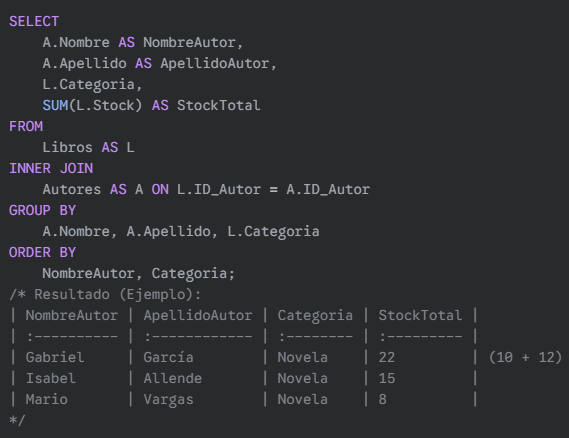
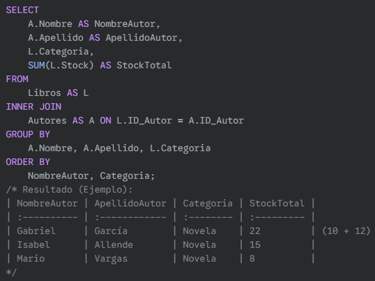
Ejemplo con múltiples columnas en GROUP BY: Calcular el stock total por cada autor y categoría.
SQL:
3. HAVING (Teniendo)
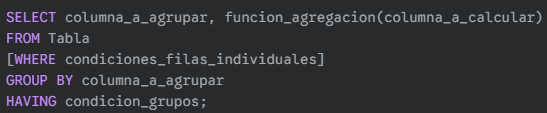
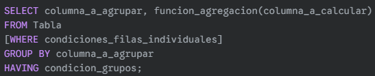
¿De qué trata? La cláusula HAVING se usa para filtrar grupos de filas que han sido creados por GROUP BY. Es similar a WHERE, pero WHERE filtra filas individuales antes del agrupamiento, mientras que HAVING filtra grupos después de que se han aplicado las funciones de agregación.
¿Cómo se hace? Se coloca después de GROUP BY y antes de ORDER BY. Sus condiciones suelen incluir funciones de agregación.
SQL:
Para copiar:
SELECT columna_a_agrupar, funcion_agregacion(columna_a_calcular)
FROM Tabla
[WHERE condiciones_filas_individuales]
GROUP BY columna_a_agrupar
HAVING condicion_grupos;
Ejemplo: Contar cuántos libros hay por categoría, pero solo mostrar las categorías que tienen más de 1 libro.
SQL:
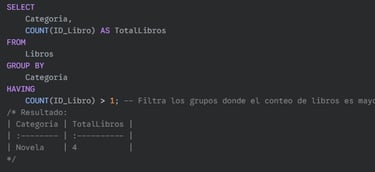
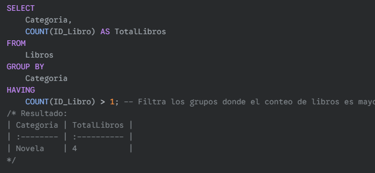
Para copiar:
SELECT
Categoria,
COUNT(ID_Libro) AS TotalLibros
FROM
Libros
GROUP BY
Categoria
HAVING
COUNT(ID_Libro) > 1;
4. Subconsultas (Subqueries / Nested Queries)
¿De qué trata? Una subconsulta es una consulta SELECT anidada dentro de otra consulta SQL. La subconsulta se ejecuta primero y su resultado se utiliza como entrada para la consulta externa. Son muy útiles para realizar operaciones que requieren dos pasos de lógica o para usar el resultado de una consulta como un valor de comparación para otra.
¿Cómo se hace? Se encierran entre paréntesis (). Pueden aparecer en varias cláusulas: SELECT, FROM, WHERE, HAVING, etc.
Ejemplos:
Subconsulta en la cláusula WHERE (para filtrar): Obtener los libros cuyo precio es mayor que el precio promedio de todos los libros.
SQL:
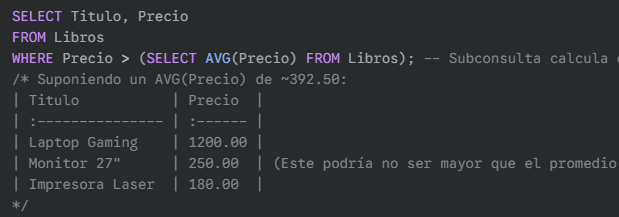
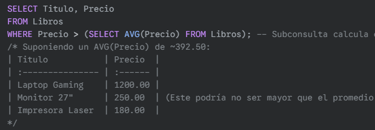
Subconsulta en la cláusula FROM (como tabla derivada): Encontrar los autores que han publicado libros antes del año 1970.
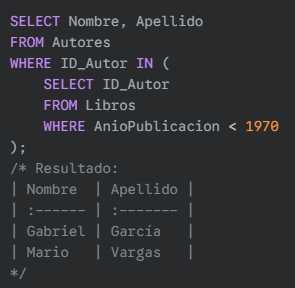
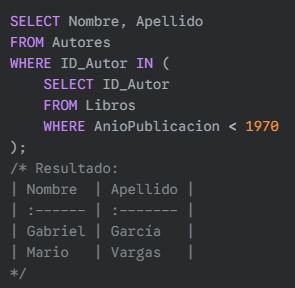
SQL:
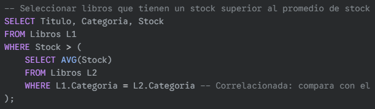
Subconsulta correlacionada (más compleja): Una subconsulta correlacionada se ejecuta una vez por cada fila de la consulta externa.
SQL: